This document demonstrates how to perform Principal Component Analysis (PCA) in R using the tidymodels framework. PCA is a dimensionality reduction technique that transforms a set of possibly correlated variables into a set of linearly uncorrelated variables called principal components. We will use the adult_income_dataset.csv for this demonstration.
2 Load Data
First, we load the necessary libraries and the income dataset.
Code
library(tidyverse)library(tidymodels)library(factoextra)income_data <-read_csv("../data/adult_income_dataset.csv")# For simplicity, we'll remove rows with any missing values and the 'income' columnincome_data_clean <- income_data %>%select(-income) %>%na.omit() %>%sample_n(1000) # Randomly sample 10,000 rows# Preprocessing using recipesincome_recipe <-recipe(~ ., data = income_data_clean) %>%step_rm(all_nominal_predictors()) %>%# One-hot encode all nominal (categorical) predictorsstep_normalize(all_numeric_predictors()) %>%# Normalize all numerical predictorsprep(training = income_data_clean)income_data_processed <-bake(income_recipe, new_data = income_data_clean)# Remove any columns that might have resulted in all zeros after one-hot encoding if they were constantincome_data_processed <- income_data_processed[, colSums(income_data_processed) !=0]
We will perform PCA on the preprocessed income data.
Code
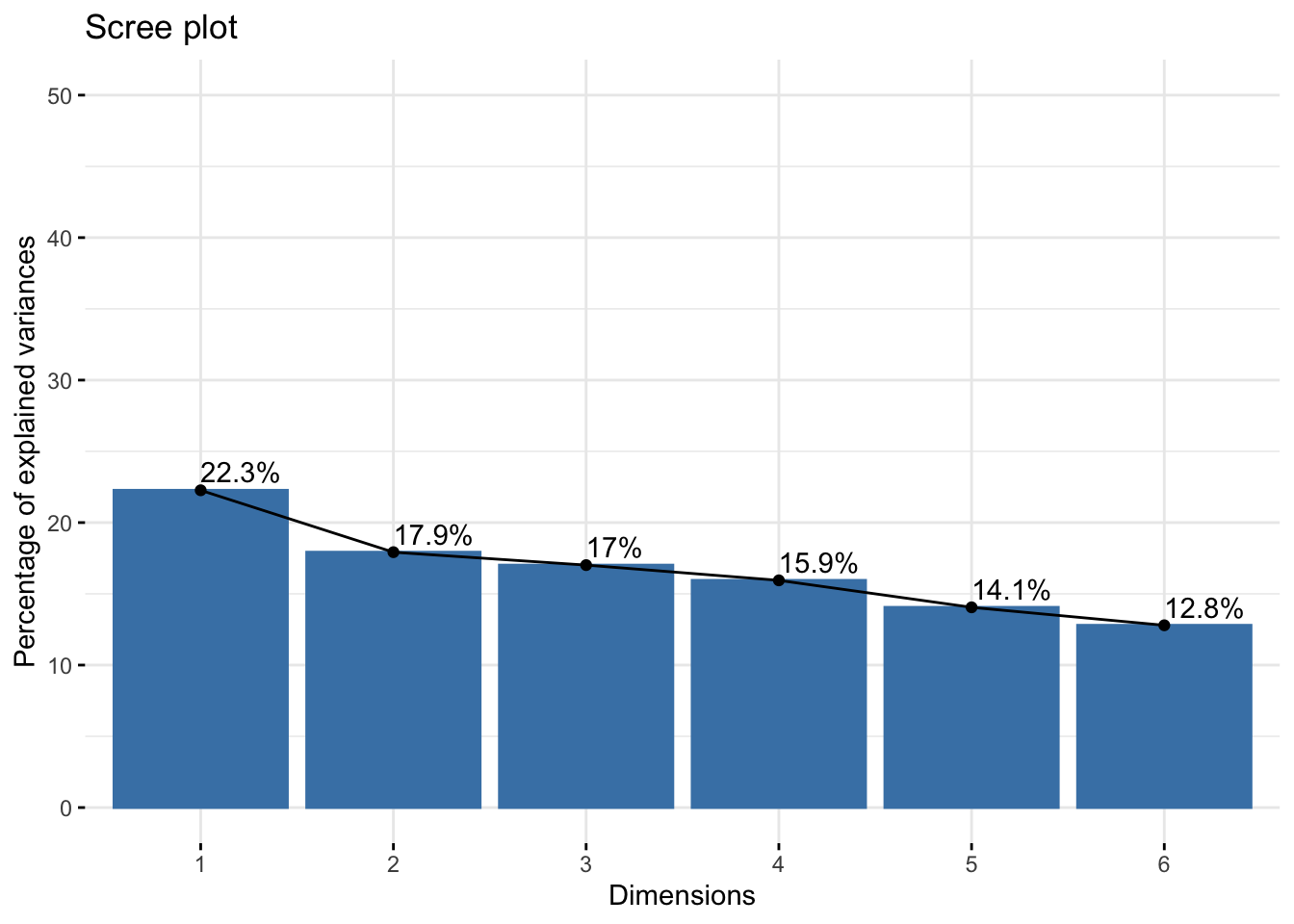
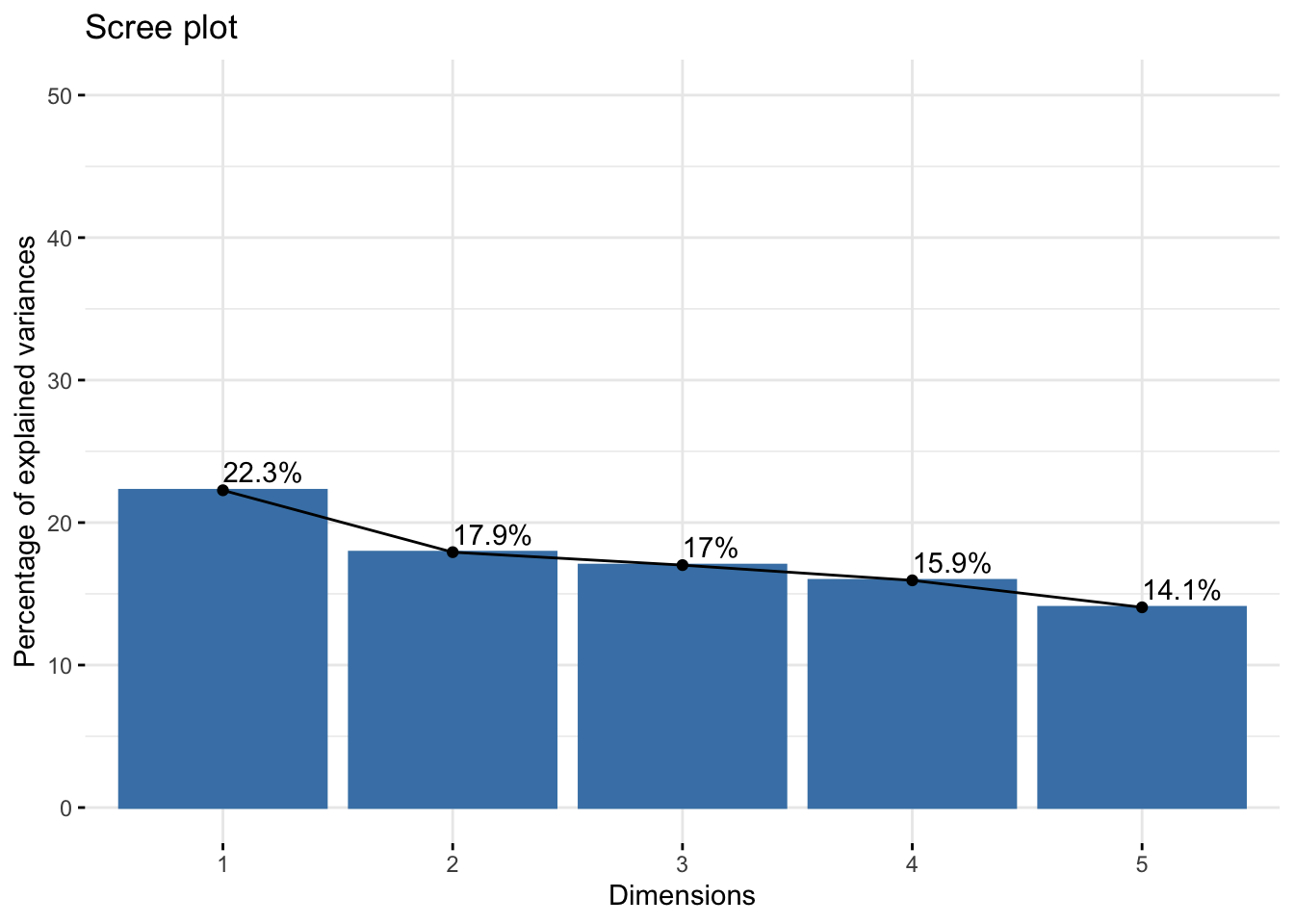
# Perform PCAres.pca <-prcomp(income_data_processed, scale =FALSE) # Data is already scaled# Visualize eigenvalues (scree plot)fviz_eig(res.pca, addlabels =TRUE, ylim =c(0, 50))
4 PCA Results Visualization
We can visualize the results of PCA, including the contribution of variables to the principal components and the individuals’ positions.
Code
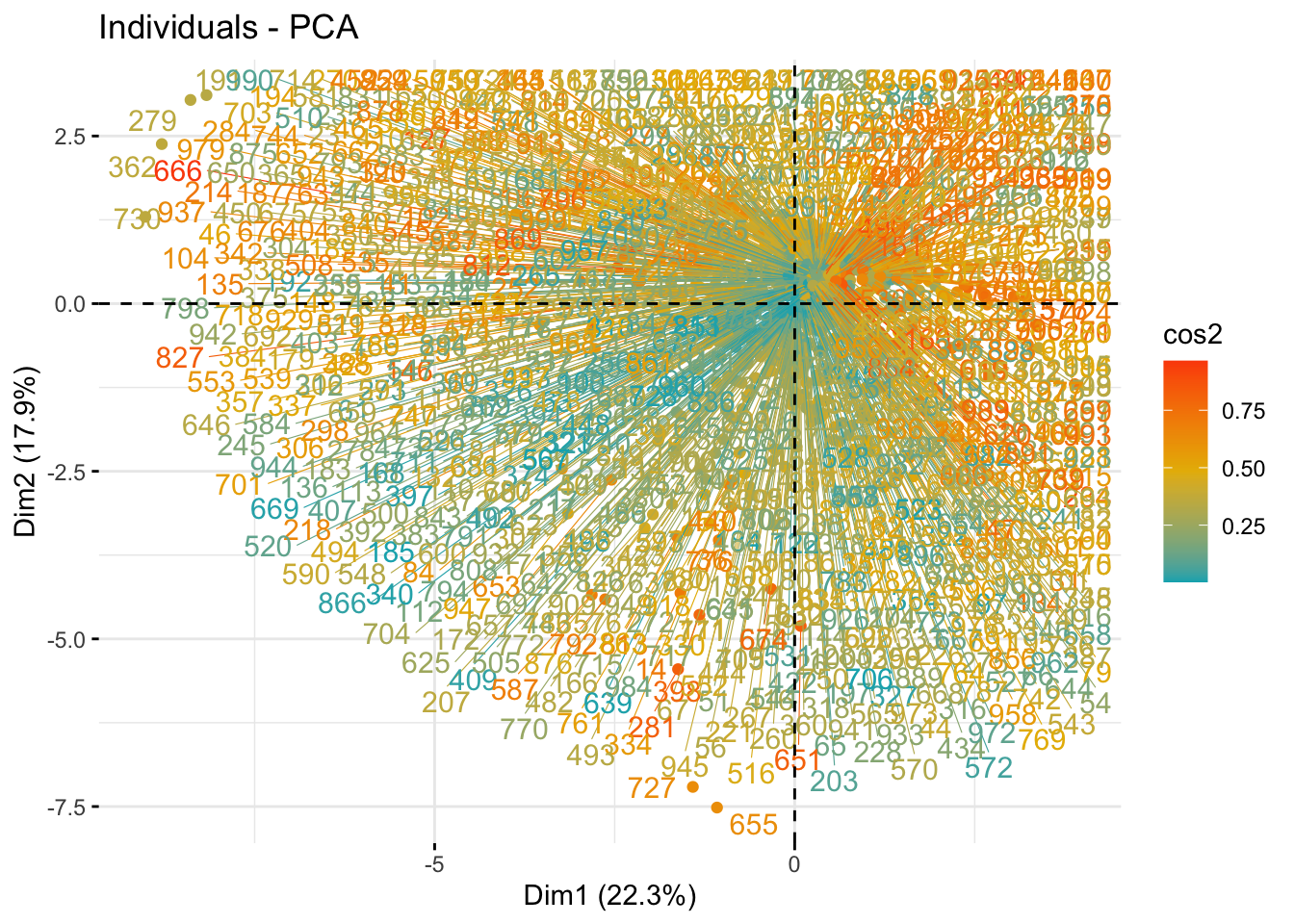
# Plot of individuals on the first two principal componentsfviz_pca_ind(res.pca,col.ind ="cos2", # Color by the quality of representationgradient.cols =c("#00AFBB", "#E7B800", "#FC4E07"),repel =TRUE, # Avoid text overlappingggtheme =theme_minimal() )
Code
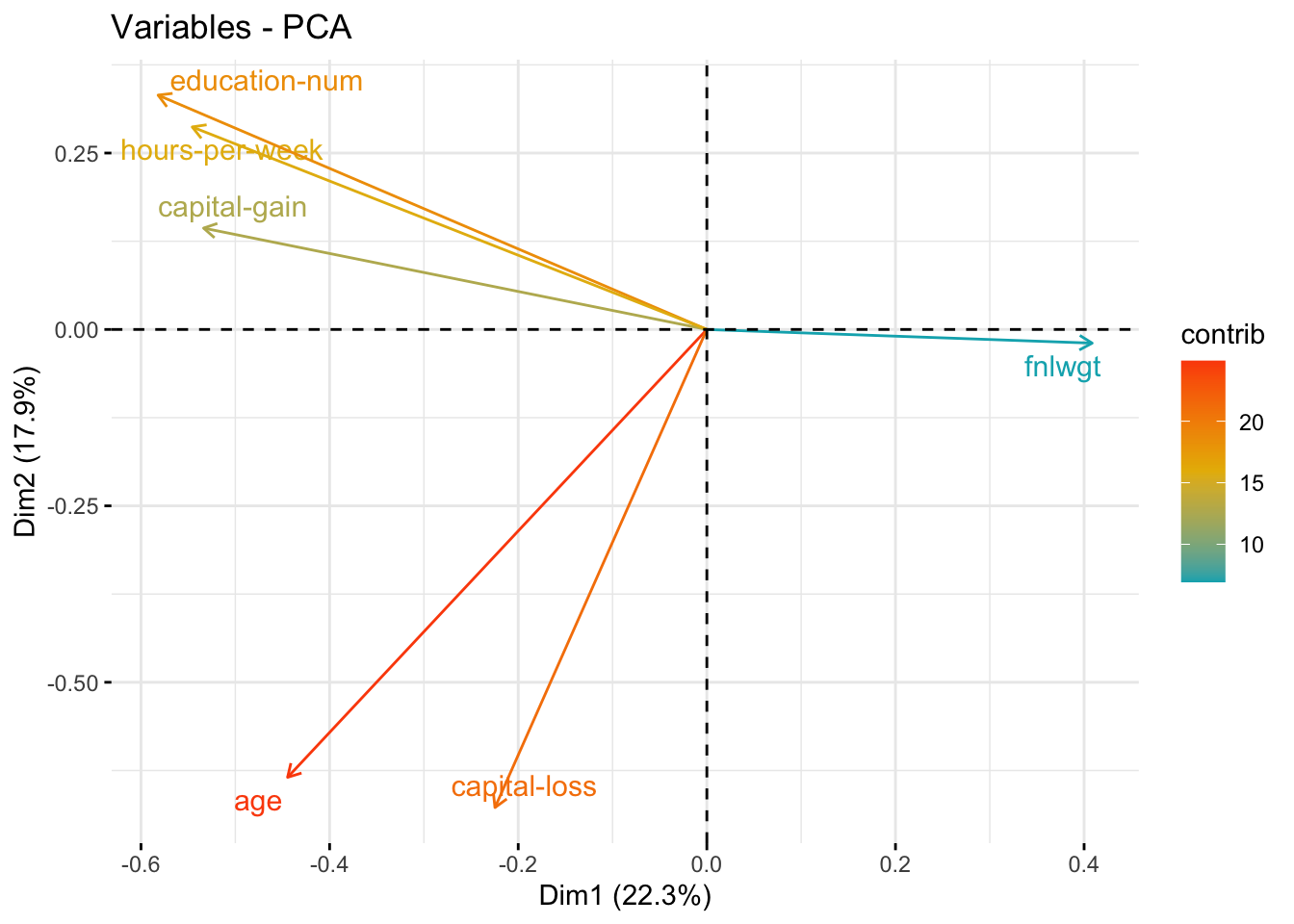
# Plot of variablesfviz_pca_var(res.pca,col.var ="contrib", # Color by contributions to the PCgradient.cols =c("#00AFBB", "#E7B800", "#FC4E07"),repel =TRUE, # Avoid text overlappingggtheme =theme_minimal() )
Code
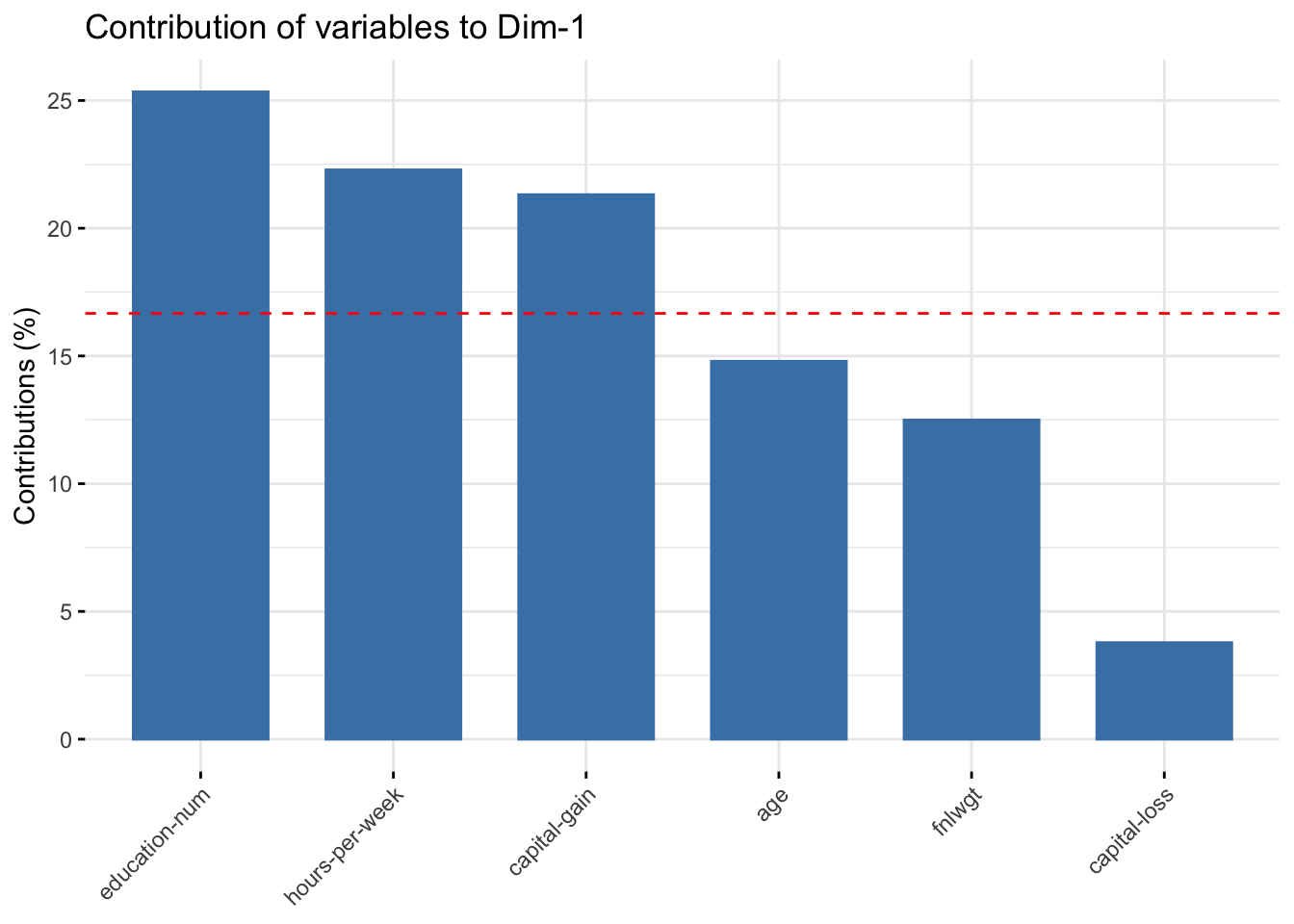
# Contributions of variables to PC1fviz_contrib(res.pca, choice ="var", axes =1, top =10)
Code
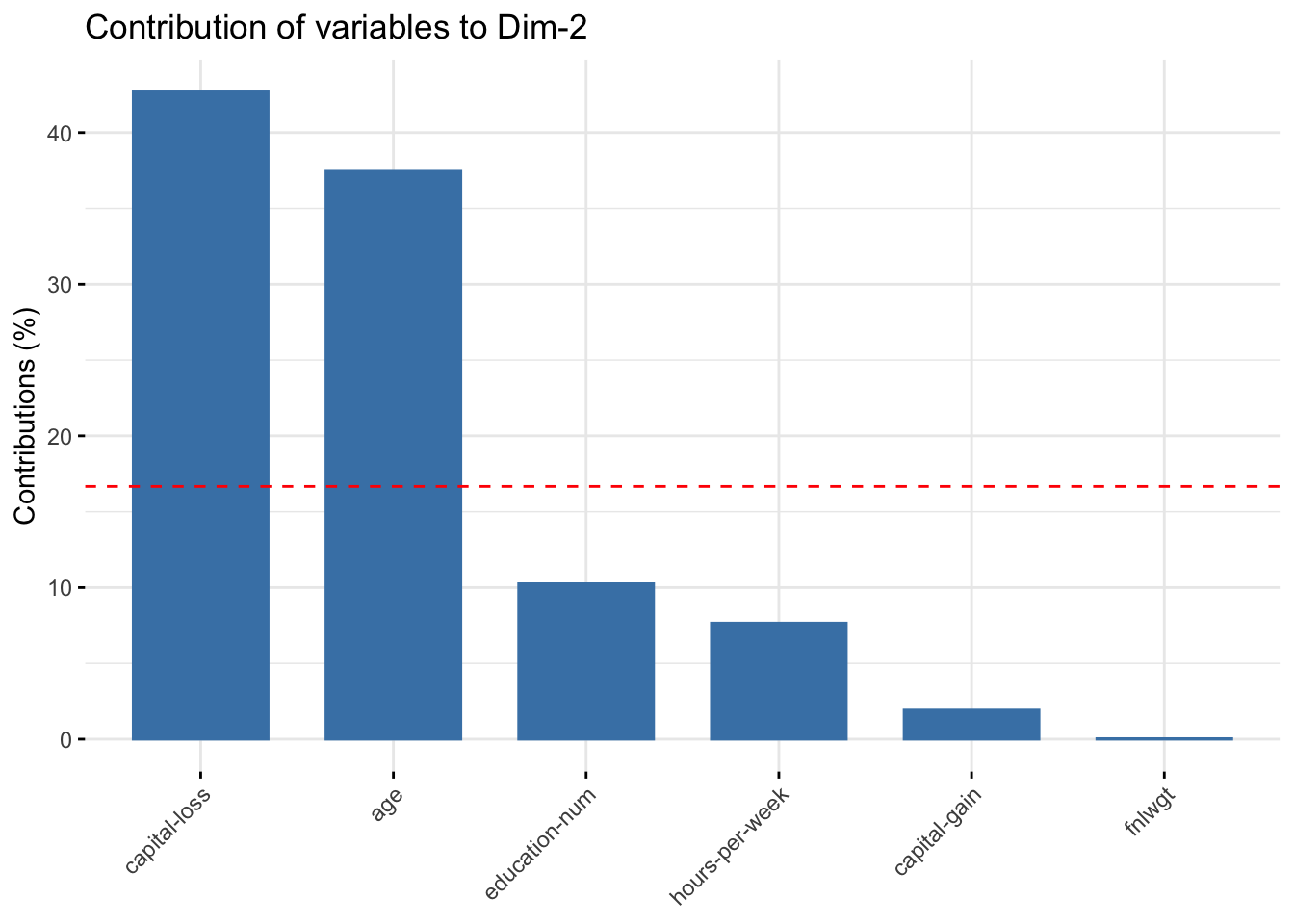
# Contributions of variables to PC2fviz_contrib(res.pca, choice ="var", axes =2, top =10)
Code
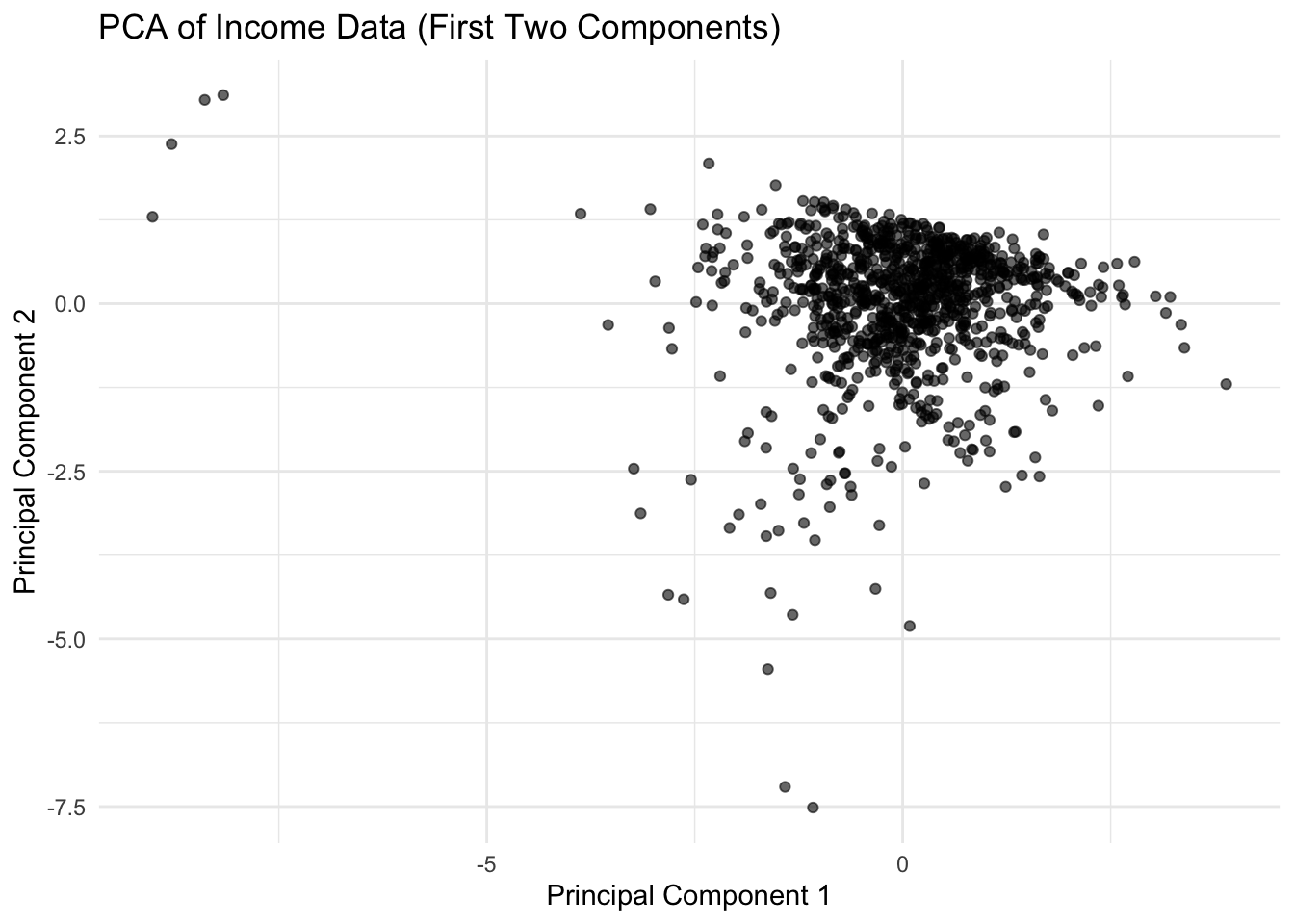
# 2D scatter plot of individuals on the first two principal components (similar to Python)# Extract the principal componentspca_coords <-as.data.frame(res.pca$x)# Plot using ggplot2ggplot(pca_coords, aes(x = PC1, y = PC2)) +geom_point(alpha =0.6) +labs(title ="PCA of Income Data (First Two Components)",x ="Principal Component 1",y ="Principal Component 2") +theme_minimal()
5 Conclusion
This document provided an overview of Principal Component Analysis in R using tidymodels. We demonstrated how to perform PCA on the income dataset and visualize the results.If your data is mostly categorical, PCA is often not the best choice. Use these instead.
6 Keeping Top 5 Components
We can select and work with a reduced number of principal components, for example, the top 5 components that explain a significant portion of the variance.
Code
# Get the principal components (coordinates of the individuals)head(res.pca$x[, 1:5])
# Visualize the variance explained by the first 5 componentsfviz_eig(res.pca, addlabels =TRUE, ylim =c(0, 50), ncp =5)
Source Code
---title: "PCA: Income Data with R"subtitle: "Using tidymodels"execute: warning: false error: falseformat: html: toc: true toc-location: right code-fold: show code-tools: true number-sections: true code-block-bg: true code-block-border-left: "#31BAE9"---## IntroductionThis document demonstrates how to perform Principal Component Analysis (PCA) in R using the `tidymodels` framework. PCA is a dimensionality reduction technique that transforms a set of possibly correlated variables into a set of linearly uncorrelated variables called principal components. We will use the `adult_income_dataset.csv` for this demonstration.## Load DataFirst, we load the necessary libraries and the income dataset.```{r}#| label: load-data#| echo: truelibrary(tidyverse)library(tidymodels)library(factoextra)income_data <-read_csv("../data/adult_income_dataset.csv")# For simplicity, we'll remove rows with any missing values and the 'income' columnincome_data_clean <- income_data %>%select(-income) %>%na.omit() %>%sample_n(1000) # Randomly sample 10,000 rows# Preprocessing using recipesincome_recipe <-recipe(~ ., data = income_data_clean) %>%step_rm(all_nominal_predictors()) %>%# One-hot encode all nominal (categorical) predictorsstep_normalize(all_numeric_predictors()) %>%# Normalize all numerical predictorsprep(training = income_data_clean)income_data_processed <-bake(income_recipe, new_data = income_data_clean)# Remove any columns that might have resulted in all zeros after one-hot encoding if they were constantincome_data_processed <- income_data_processed[, colSums(income_data_processed) !=0]``````{r}glimpse(income_data_processed)```## Principal Component AnalysisWe will perform PCA on the preprocessed income data.```{r}#| label: pca#| echo: true# Perform PCAres.pca <-prcomp(income_data_processed, scale =FALSE) # Data is already scaled# Visualize eigenvalues (scree plot)fviz_eig(res.pca, addlabels =TRUE, ylim =c(0, 50))```## PCA Results VisualizationWe can visualize the results of PCA, including the contribution of variables to the principal components and the individuals' positions.```{r}#| label: pca-viz#| echo: true# Plot of individuals on the first two principal componentsfviz_pca_ind(res.pca,col.ind ="cos2", # Color by the quality of representationgradient.cols =c("#00AFBB", "#E7B800", "#FC4E07"),repel =TRUE, # Avoid text overlappingggtheme =theme_minimal() )# Plot of variablesfviz_pca_var(res.pca,col.var ="contrib", # Color by contributions to the PCgradient.cols =c("#00AFBB", "#E7B800", "#FC4E07"),repel =TRUE, # Avoid text overlappingggtheme =theme_minimal() )# Contributions of variables to PC1fviz_contrib(res.pca, choice ="var", axes =1, top =10)# Contributions of variables to PC2fviz_contrib(res.pca, choice ="var", axes =2, top =10)# 2D scatter plot of individuals on the first two principal components (similar to Python)# Extract the principal componentspca_coords <-as.data.frame(res.pca$x)# Plot using ggplot2ggplot(pca_coords, aes(x = PC1, y = PC2)) +geom_point(alpha =0.6) +labs(title ="PCA of Income Data (First Two Components)",x ="Principal Component 1",y ="Principal Component 2") +theme_minimal()```## ConclusionThis document provided an overview of Principal Component Analysis in R using `tidymodels`. We demonstrated how to perform PCA on the income dataset and visualize the results.If your data is mostly categorical, PCA is often not the best choice. Use these instead.## Keeping Top 5 ComponentsWe can select and work with a reduced number of principal components, for example, the top 5 components that explain a significant portion of the variance.```{r}#| label: top-5-components-r#| echo: true# Get the principal components (coordinates of the individuals)head(res.pca$x[, 1:5])# Get the loadings (eigenvectors)head(res.pca$rotation[, 1:5])# Visualize the variance explained by the first 5 componentsfviz_eig(res.pca, addlabels =TRUE, ylim =c(0, 50), ncp =5)```